The Conjecture framework provides a collection of kernel classes
(including the \ref kernel "Element" hierarchy discussed elsewhere).
Classes like Page, Line, and Glyph are of use to any OCR
implementation. Furthermore, the Page class provides fundamental
methods like 'segment' (responsible for identifying Glyphs within the
Image associated with the Page), 'identify' (responsible for
identifying unicode characters for each Glyph), and 'format'
(responsible properly formatting the identified characters into words,
lines, paragraphs, columns, pages, etc.)
In order to explain both the overall Conjecture architecture, and the
rationale behind the architecture, we will first look at some initial
solutions to the problem of customization. The Conjecture framework is
supposed to make it easy for individuals to contribute anything from
tiny within-method improvements to single-method reimplementations to
entirely new algorithms to entirely new fully-functional OCRs.
Suppose we limit ourselves to just the Element hierarchy for now, and
consider how an individual can extend the framework. Since the Page
class defines issue-solving methods like 'segment()', 'identify()',
and 'format()', one natural means of customization is to introduce a
subclass of Page and redefine the methods one wants to experiment
with. For example, an individual could create a MyPage class, and
could redefine 'segment() in order to write a better glyph segmenting
algorithm, or redefine 'identify()' in order to write a better glyph
identification algorithm. This strategy is both straight-forward and
intuitive. However, it also suffers from a serious drawback.
Specifically, there are many possible implementations of the 'segment'
algorithm, many possible implementations of the 'identify' algorithm,
and in general many different implementations of all the various
issues related to OCR. Suppose there are K variants for 'segment()', L
variants of 'identify' and M variants of 'format()'. Using the
strategy of subclassing Page and redefining relevant methods to
provide extension, we would need to create K * L * M 'Page' subclasses
in order to represent all combinations of the various implementations.
Depending on the values of K, L and M, this number can quickly become
prohibitive, and that assumes there will only be 3 issue-solving
methods defined on Page (which isn't true at all - there will probably
be 20 or more such methods, each with many possible implementations).
Having explained why subclassing the Element hierarchy to support
extension can be problematic, we can now explain what the Conjecture
framework does to address the problem. As is usually the case, adding
a level of abstraction makes everything sunny and happy. Although this
extra level of abstraction makes the overall architecuture more
complex, and thus somewhat more difficult to grasp at first, the
flexibility it provides in allowing incremental improvements is well
worth the increase in complexity.
As an example, Conjecture has formalized the concept of 'segmentation'
(finding Glyphs within an Image) into a SegmentComponent class
hierarchy. The abstract SegmentComponent class defines an interface,
and subclasses provide an implementation of that interface.
Similarily, the concept of 'identification' (establishing unicode
values for each Glyph) has been formalized into the IdentifyComponent,
and so on. As new issues are identified, new component hierarchies
will be added to the Conjecture framework.
So far, Conjecture has identified three fundamental issues: Segment,
Identify and Format. However, Conjecture will be providing
decompositions of each of these components into sub-components. For
example, dust removal, page orientation, and font-detection are all
possible sub-issues of segmentation that could be formalized into
Component hierarchies.
The fact that components can be implemented in terms of other
components highlights some important issues. First, it implies that
there are some constraints between components, and the order in which
certain components are performed may (or may not) be important,
depending on the particular component(s) in question. Furthermore, we
have already demonstrated the decomposition of components by
implicitly assuming that every OCR will perform segmentation,
identification and formatting. Although this is probably true, in the
interests of completely generality, Conjecture has also formalized the
entire OCR process into a ProcessModule. More on this later.
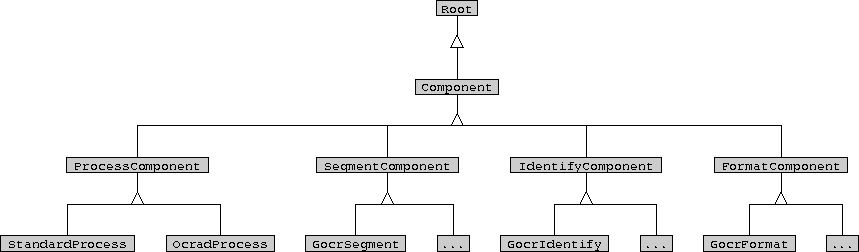
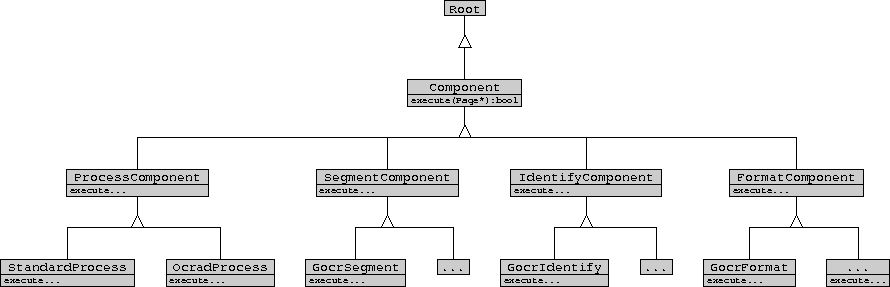
The Component-related class diagram of Conjecture currently looks like
this:
Notice that the four issues that Conjecture has currently formalized
exist as subclass hierarchies of an abstract Component class. The
ProcessComponent class defines an interface (collection of methods)
that together are responsible for the entire optical character
recognition process. Currently, the interface for all classes consists
of a single 'execute(Page* page)' method, although more methods may be
added to individual Component hierarchies as the framework evolves.
Subclasses of the Component hierarchies provide alternative
implementations. For example, the StandardProcess subclass of
ProcessComponent provides what will probably be the most common
implementation of the Process component - perform segementation, then
identification, then formatting. This default implementation knows
that the concepts of segmentation, identification and formatting have
been formalized into Components of their own, and thus, when it wants
to perform segmentation, asks the Conjecture environment for an object
that implements the SegmentComponent interface. Once it has obtained
this object, it can invoke the 'execute(Page*page)' method on it
(because it knows that this method is part of the SegmentComponent
interface). The StandardProcess class needs to know absolutely nothing
about the actual subclass of SegmentComponent being used in order to
provide segmentation. This means that the StandardProcess class can
work with any SegmentComponent (and any IdentifyComponent and
FormatComponent), making the framework highly modular and flexible.
The OcradProcess subclass of ProcessComponent does something different
than StandardProcess. Instead of decomposing the problem into
segmentation, identification and formatting, this class instead
invokes the "ocrad" executable as a subprocess. Whether 'ocrad'
decomposes the problem into segmentation, identification and
formatting is irrelevant from the perspective of the OcradProcess
class. All it knows is that it is responsible for taking an input
image and producing output text. It knows that the 'ocrad' executable
can do that, and thus, by invoking 'ocrad', it satisfies its mandate.
The OcradProcess is interesting because it demonstrates how Conjecture
can be used to interact with arbitrary third-party OCRs (including
even commercial ones, as long as they have a command-line interface).
Note also that the current implementation of OcradProcess will be
changing soon. Although delegation to an executable is sometimes
useful, Conjecture is about identifying and extending existing
algorithms for solving OCR problems, and as such it is much better to
link the Ocrad source code into Conjecture so that programmers have
access to the internals and can incrementally improve upon or borrow
from its implementation in the creation of new algorithms.